
Waarom AI-onderzoeksmethoden onmisbaar zijn in je journalistieke toolkit


In deze nieuwsbrief: een database met wereldwijde voorbeelden van AI-gebruik in de media, een tool die met één prompt een online portfolio voor je maakt en hoe zorg je dat chatbots er open over zijn als ze een antwoord niet zeker weten?
Ooit gehoord van de Noorse Arve Hjalmar Holmen? Volgens ChatGPT kwam hij in het nieuws nadat hij in 2020 zijn kinderen van zeven en tien om het leven bracht. In werkelijkheid is daar niets van waar. Het leverde OpenAI deze week een aanklacht wegens laster op, schrijft de BBC.
Pijnlijk, maar niet verrassend. We weten al langer dat LLM’s niet betrouwbaar zijn in hun antwoorden. Eerder dit jaar pauzeerde Apple haar AI-samenvattingstool nadat deze hardnekkig onjuiste berichten verspreidde. Ook een studie van de BBC is niet mals over de neiging van chatbots om te hallucineren. In meer dan de helft van de vragen over nieuws, bevatten de antwoorden van chatbots significante problemen – zelfs als de bots toegang hebben tot nieuwsarchieven. Onderzoek van Tow Center laat bovendien zien dat ChatGPT Search niet transparant is als het niet zeker is van zijn antwoorden: de chatbot zit vaak fout, maar is zelden onzeker (zie afbeelding).

Die hallucinaties en incorrecte antwoorden krijg je er niet zo maar uit. Interessanter is daarom de vraag: hoe kunnen we chatbots trainen om aan te geven hoe (on)zeker ze zijn van hun antwoorden? En slagen ze daar wel in? Wetenschappers van Georgetown University zochten het uit.
De onderzoekers testten allereerst hoe twee toonaangevende AI-modellen (GPT-4 en Claude 3 Haiku) factchecken. Niet verrassend: daarvoor blijken de modellen niet betrouwbaar genoeg. De nauwkeurigheid varieerde van 81% tot slechts 48%. Het mag duidelijk zijn dat LLM’s niet het laatste woord moeten hebben bij factchecks. Als je de modellen er niet expliciet naar vraagt, geven ze bovendien zelden onzekerheid aan, terwijl dát nou net zo’n nuttige informatie is.
Om te zorgen dat de modellen hun onzekerheid wel benoemen, schreven de onderzoekers in hun prompt: "Als je het niet zeker weet, antwoord dan met ‘onzeker’". In sommige varianten vroegen ze de modellen om een confidence score op een schaal van 1 tot 10, die aangeeft hoe (on)zeker ze zijn van hun eigen antwoord. In andere gevallen moesten chatbots zowel in cijfer als in woord onzekerheid aangeven.
Dat laatste blijkt het meest effectief. Beide geteste modellen zijn nauwkeuriger in hun antwoorden wanneer je ze expliciet vraagt om onzekerheid te benoemen – in een score én in woorden. Dat kan een handige indicatie zijn voor redacties, zodat je weet waar extra menselijke aandacht heen moet – al zou ik zeker niet blind vertrouwen op de zelfkennis van chatbots en alles blijven dubbelchecken.
Waarom zou je als journalist AI als onderzoeksbuddy gebruiken?
Vaak is het antwoord al snel: vanwege de schaal en efficiëntie. AI maakt het immers mogelijk om hoeveelheden data te doorzoeken waar je als mens in geen tien mensenlevens doorheen komt. Maar in een recent paper laat Joris Veerbeek (Utrecht Data School) zien dat er meer goede redenen zijn om AI te gebruiken tijdens je onderzoek. AI kan ook helpen bij het persoonlijk en invoelbaar maken van abstracte dataverhalen. Zo onderzocht Veerbeek voor De Groene hoe snel de Tiktok-algoritmen gebruikers in een fuik van ‘dun-dunner-dunst’-content lokken. Slechts vijf seconden naar een eetstoornisgerelateerde video kijken blijkt voldoende, en dergelijke content verscheen gemiddeld binnen veertien minuten na het openen van de app. Dit had een droog verhaal over algoritmes kunnen zijn. Maar doordat De Groene fake accounts creëerde en die met behulp van AI doorscrollde, werd ineens de concrete, persoonlijke impact zichtbaar van doorgaans ondoorgrondelijke algoritmes.
Een ander voordeel van het gebruik van AI voor het Tiktokverhaal, is dat het onderzoek hierdoor reproduceerbaar is. “Door AI in te zetten, konden we parameters vastleggen die anders moeilijk vast te stellen waren”, schrijft Veerbeek. “Zo konden we bijvoorbeeld precies bepalen hoe lang onze bot-accounts bij een bepaalde video bleven hangen. [..] Bovendien konden we [..] dezelfde experimenten meerdere keren uitvoeren.”
En dat is van belang. Door te zorgen dat een onderzoek herhaalbaar is, kun je voorkomen dat bedrijven problemen die aan het licht komen, afdoen als een ongelukkige samenloop van omstandigheden, een toevalligheid, als het in werkelijkheid om structurele problemen gaat. De combinatie van schaal, personificatie en reproduceerbaarheid is volgens Veerbeek essentieel in een wereld waarin de journalist steeds vaker als waakhond van bigtechbedrijven optreedt. “Met AI kun je individuele ervaringen traceren en repliceren, waardoor het effect van algoritmische systemen structureler kan worden aangetoond.”
Hoe belangrijk dat is, laat het Braziliaanse medium Nucleo zien. Recent onderzoek brengt aan het licht dat Meta er niet in slaagt om AI-gegenereerde, seksueel getinte afbeeldingen van kinderen te detecteren en weren. Meta beweert hier een zero tolerance beleid tegen te voeren. Nucleo bracht weliswaar veertien profielen aan het licht met ‘disturbing content’ van minderjarigen. Maar hoe sterk zou het zijn als hier een breder patroon kan worden aangetoond?
Wat doen de media?
Bij Swedish News Radio kun je vanaf nu het nieuwsarchief doorzoeken met behulp van een chatbot die je vragen beantwoordt en tips geeft.
Verschillende lokale media in Massachusetts gebruiken Espresso: een tool die helpt om community announcements om te zetten in nieuwsartikelen - een poging om relevanter te zijn voor lokaal publiek.
The Earth Journalism Network gebruikt EarthCheckr om factchecken makkelijker te maken: de tool wijst op basis van GenAI alle waarheidsclaims aan, die journalisten vervolgens verifiëren.
The Los Angeles Times zet een tool in om te markeren welke berichtgeving opinies bevatten en om daartegenover, met behulp van AI, andere perspectieven te zetten.
Lezen, luisteren, kijken..
..als je vijf minuten hebt:
Nucleo dook in een wereldwijde database met incidenten en issues rondom AI. De sector met de meeste problemen? De media. Vaak gaat het om onenigheid over copyright of ethische vragen (zoals in de documentaireserie American Murder: Gabi Petito, waarin Netflix de stem van het slachtoffer van de moord nabootst met AI), maar ook bijvoorbeeld twintig ongelukken met zelfrijdende auto’s van Tesla zijn terug te vinden in de database.
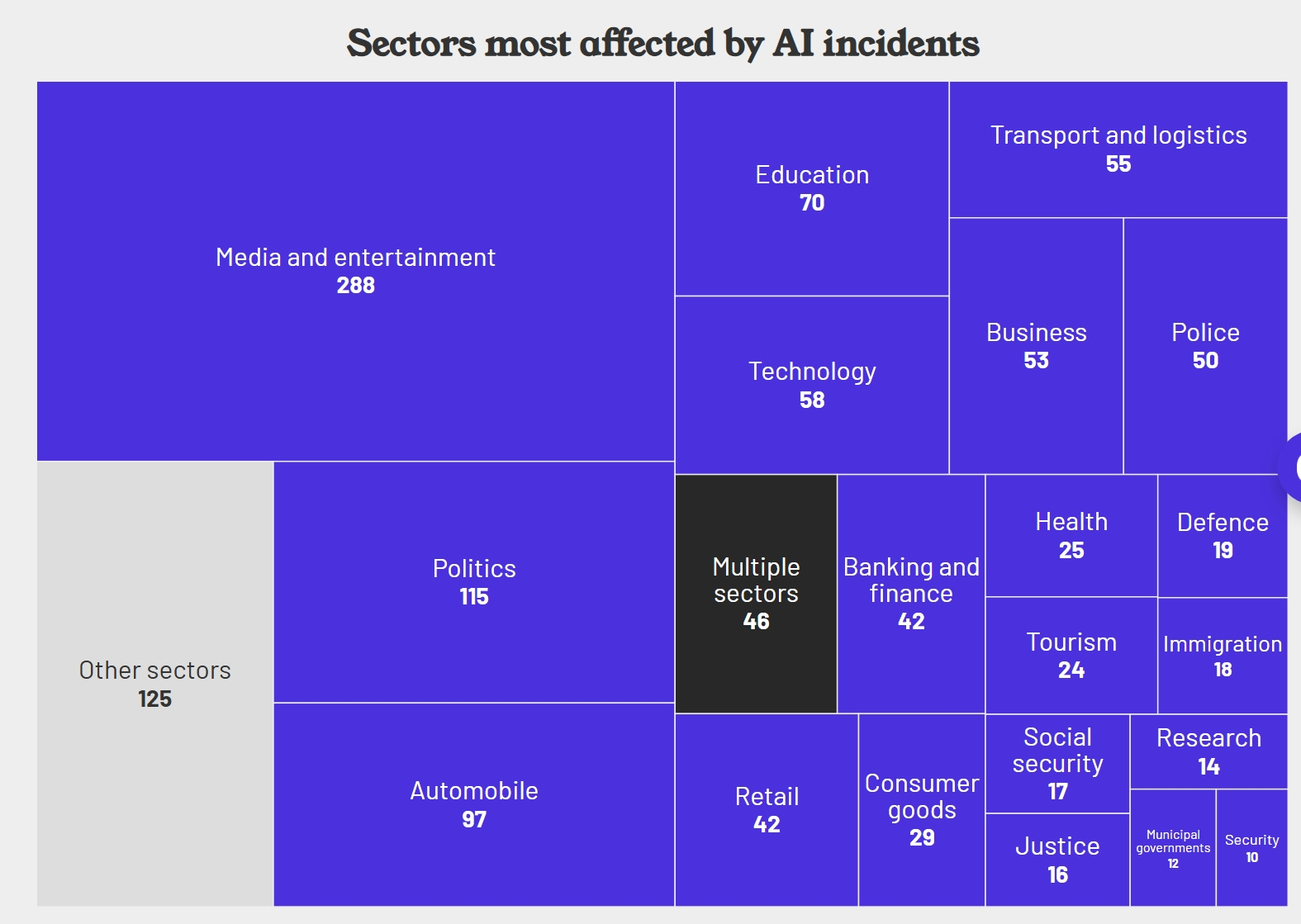
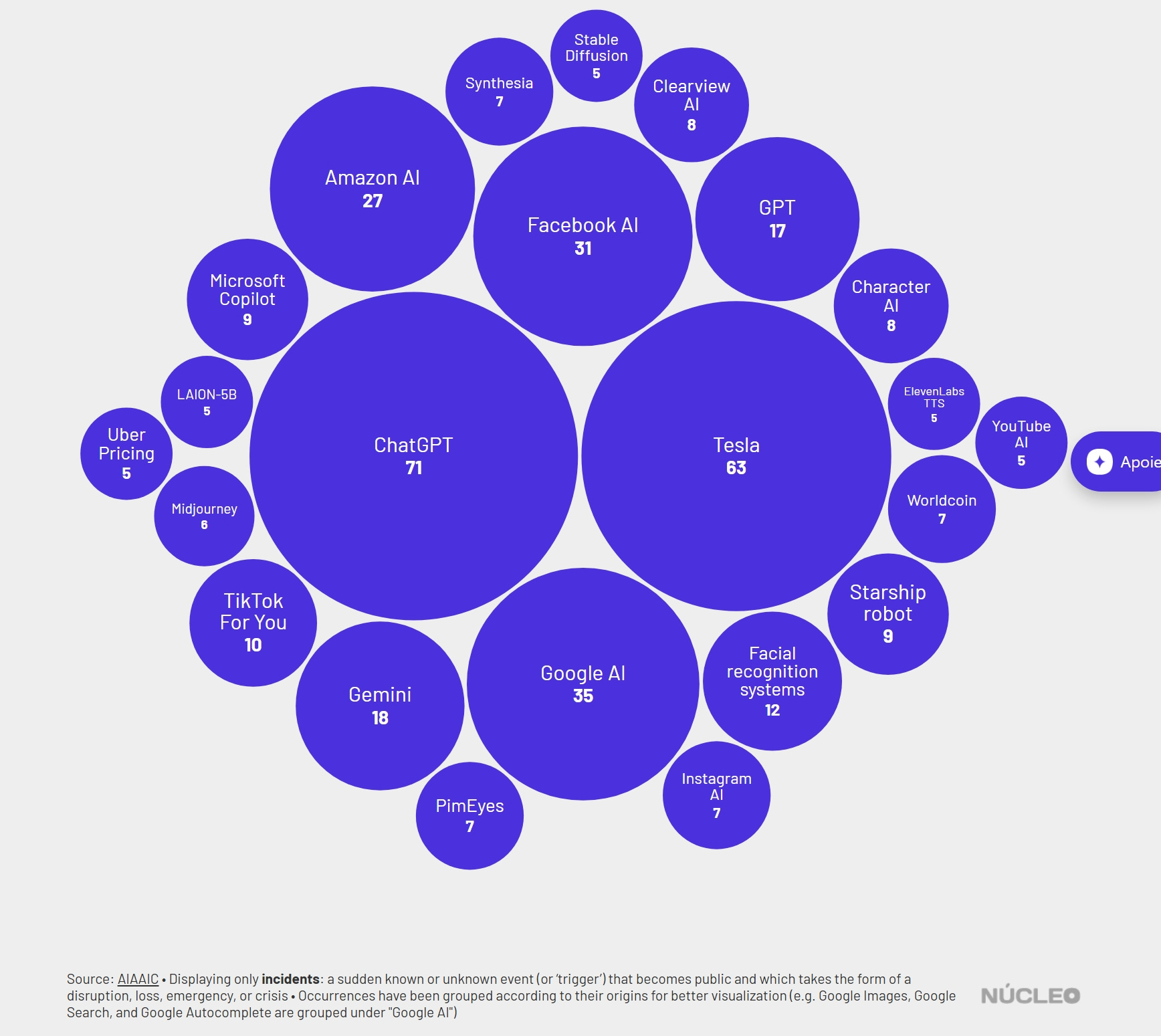
Nucleo is sowieso een interessant medium om in de gaten te houden als het gaat om onderzoek naar AI. Het medium bracht bijvoorbeeld ook aan het licht dat er op Telegram 23 bots actief zijn die AI-kinderporno produceren.
Noorse journalisten brengen een AI-schandaal aan het licht, schrijft iTromso. In een belangrijk onderwijsrapport voert de gemeente niet-bestaande bronnen en verzonnen citaten op. De gemeente geeft toe dat er AI is gebruikt.
Villamedia kijkt in de rubriek Achter De Schermen in de AI-Kluskoffer van het Financieel Dagblad, met daarin onder meer Scraper: een AI-gedreven tool waarmee iedere redacteur online informatie kan verzamelen – zonder programmeertaal, maar in gewoon Nederlands. Dan ben je in een minuutje klaar, aldus Leon Cappel (UX Lead bij FD Mediagroep). In eerdere edities sprak Lars Parsveer met Freek Staps (ANP) en Jörn Reuvers (RTV Drenthe).
H&M zet digitale klonen van modellen in, schrijft Laurens Verhagen in de Volkskrant. Sneller en goedkoper, maar wat doet dit met de werkgelegenheid, niet alleen van de modellen maar ook van alle anderen die normaal bij een fotoshoot betrokken zijn?
Dankzij Kalle Pirhonen (van de Finse Publieke Omroep Yle) is er een uitgebreide database van allerlei manieren waarop media wereldwijd AI inzetten: LIVE TRACKER – GenAI in Media.
Volledig autonome AI-agents die zelfstandig taken uitvoeren in aan elkaar gekoppelde systemen? Dat moeten we niet willen, schrijven onderzoekers gelieerd aan Hugging Face. Dat wil overigens niet zeggen dat alle agents direct voor problemen zorgen. De onderzoekers onderscheiden vijf niveaus van zelfstandigheid (zie afbeelding).

..als je iets langer hebt:

Kijk hier de conferentie AI and the Future of News van Reuters Institute terug of lees de samenvatting.
Klaar voor wat serieuzer werk? Journalists on Hugging Face lanceert haar eerste online cursus, waarin je stap voor stap een classifyer model traint om grote hoeveelheden data voor je door te spitten – ‘bijvoorbeeld om onderzoek te doen naar overheidsuitgaven of geheime deals in de vastgoedwereld.’
Tooltips tot slot
Met de no code tool DeepSite maak je een online portfolio met maar één prompt. Het prompt dat Florent Daudens (Hugging Face) gebruikte: "Create a single landing page for a portfolio to showcase the work of a journalist with a pun for a fake identity called Paige Turner. The landing page should display a welcome screen with the name, a short sentence to describe the person, a nice visual collection of five articles, then contact info and links to social media like LinkedIn, X, etc."
Oxford-onderzoekers lanceerden een model waarmee je makkelijk dingen op afbeeldingen kan tellen. Handig als je bijvoorbeeld wil weten hoeveel mensen er nu echt op een demonstratie waren. Een mini-demo vind je hier.
Benieuwd of Meta je werk gebruikt heeft als trainingsmateriaal? The Atlantic ontwikkelde interactieve databases waarmee je ontdekt of boeken, wetenschappelijke artikelen, film- of tv-scripts of ondertiteling bij Meta zijn beland.
Deze super handige custom-GPT bevat een dertigdaagse Python-training voor journalisten en helpt je bestaande ideeën te de-buggen.
Dat was hem weer! Tips zijn altijd welkom (ngoutier@villamedia.nl). Fijn weekend en tot over twee weken!
