
Media & AI in 2034: wat we leren van scenario-onderzoek

“De enige technologie die zich sneller ontwikkelt dan zelfs insiders verwacht hadden, is AI”, verkondigde Bill Gates onlangs. Wat betekent dat voor de media en hoe bereiden we hierop ons voor? Zonder glazen bol bol geen makkelijke vragen om te beantwoorden. Daarom duik ik in drie scenario-onderzoeken die mogelijke toekomstige ontwikkelingen verkennen en sprak ik Ezra Eeman (Directeur Strategie & Innovatie bij de NPO).
Scenario-onderzoek gaat ongeveer zo: een interdisciplinaire groep staat stil bij de verschillende trends die invloed hebben op media & AI (politiek, economisch, technologisch, sociaal) om te bedenken welke toekomstscenario’s denkbaar zijn. De uitkomst is niet één voorspelling, maar een reeks mogelijke scenario’s, waarmee organisaties zich gerichter op de toekomst kunnen voorbereiden. “AI wordt een bepalende kracht binnen de media”, voorspelt Ezra Eeman (NPO). “We zijn ervan overtuigd dat AI onontkoombaar is en dat we keuzes moeten maken over de manier waarop we het omarmen.”
Op welke manier zijn jullie bezig met scenario-onderzoek?
“Om zoveel mogelijk perspectieven mee te nemen, hebben we vorige week een Thinkaton georganiseerd, waarbij een dertigtal mensen van alle lagen samen nadacht over de toekomst: nieuwsconsumenten, AI-ontwikkelaars, hogescholen, universiteiten, makers, mensen van de omroepen.”
Met welke kaders werk je in zo’n Thinkaton?
“We vroegen de deelnemers: Hoe zien jullie de ontwikkeling van een medialandschap waarin AI een cruciale rol speelt en wat betekent dit voor de publieke omroep? Die vragen bekeken we vanuit drie invalshoeken: vanuit het publiek, vanuit de maker en vanuit de maatschappelijke impact. Er is een aantal drijvende krachten waar je rekening mee moet houden bij het formuleren van scenario’s. Natuurlijk de technologie (wat kan die in de toekomst?), maar ook de consument (wat zal de houding tegenover AI zijn?), de markt (wordt die bijvoorbeeld gedomineerd door enkele grote spelers?) en wet- en regelgeving. In de gesprekken hebben we bovendien een aantal voorspellingen meegenomen uit een toekomstscenario dat we eerder intern formuleerden.”

Welke voorspellingen zijn dat?
“Allereerst dat het onderscheid tussen data en media bijna niet meer te maken zal zijn. Elk datapunt kan content worden. Doordat content vloeibaar wordt, zal er een overvloed aan zijn, terwijl aan originaliteit schaarste komt.
Ten tweede beschrijven we het spanningsveld tussen het mondiale mediaveld en hyperlocale content. Door AI vervagen grenzen. Iets wat in Spanje wordt gemaakt, kan hier hercreëerd worden, zodat het aanvoelt als Nederlandse content, wellicht zelfs door de context aan te passen en bijvoorbeeld Nederlandse plaatsnamen te gebruiken. In de toekomst zal AI dit proces mogelijk zo vlekkeloos maken dat het geheel natuurlijk aanvoelt. Wellicht komt er ook een tegenbeweging van lokale en authentieke content. Hierin zien we onze rol als NPO sterk.
Ten derde vervaagt de grens tussen maker en consument, doordat het maken van content toegankelijker wordt. En tot slot is er de dreiging dat we een gedeelde werkelijkheid verliezen, als iedereen zijn eigen media kan genereren en aanpassen aan zijn of haar eigen behoeften.”
Wat valt tot nu toe op?
“De analyse loopt nog, maar wat al snel duidelijk werd, is dat we nu al bepaalde keuzes moeten maken. Een belangrijke vraag is in hoeverre je als maker de vorm van verhalen nog kunt bepalen. Vergelijk het met legoblokjes: maak je een volledig plaatje of werk je met losse stukjes die de gebruiker zelf in elkaar zet? Wat AI doet is dezelfde data steeds op andere manieren vormgeven. In hoeverre vind je dat wenselijk? Als steeds meer mensen zelf als makers aan de slag gaan, wat betekent dat dan voor de rol van de publieke omroep? En welke stappen moeten we nu al zetten om ervoor te zorgen dat het aanbod betrouwbaar is, van creatie tot levering?
Interessant was ook om te horen wat de behoeften van het publiek zijn. Ze gaven bijvoorbeeld aan een slimme assistent te willen die hen wegwijs maakt in de overvloed aan informatie. Dit roept direct de vraag op: welke rol hebben wij? Moeten wij zo’n assistent ontwikkelen of zijn wij slechts een stukje data in zo’n tool? Willen we als NPO ook invloed hebben op de technische kant van AI-modellen of moeten we ons alleen richten op verhalen?
Een belangrijk doel van de publieke omroep is om mensen te verbinden, maar wellicht moeten we in de toekomst nadrukkelijk een rol spelen in het bepalen van een gedeelde werkelijkheid. Daarbij komt mogelijk een fysieke component kijken. We organiseren nu al meer ontmoetingen, gaan de straat op en in gesprek met mensen. Mogelijk wordt dat nog belangrijker in een tijd waarin mensen onzeker zijn over wat echt en nep is. Dit zijn allemaal kwesties die zich in 2034 heel duidelijk zullen aandienen en waar je nu al keuzes in moet maken - zeker als je een rol in de technologie wilt spelen. De bedoeling is dat de scenario’s dat duidelijker gaan maken. We gaan er de komende tijd mee aan de slag.”
Hou ons op de hoogte!
Meer scenario-onderzoek: FutureNewsCorp
Ook Natali Helberger (Hoogleraar Recht & Digitale Technologie aan de UvA) voert scenario-onderzoek uit. Ze beschrijft een scenario dat zich afspeelt in 2034, genaamd FutureNewsCorp. Dit is de naam van een bedrijf dat fungeert als een alles-in-één service: alle technische diensten voor het produceren en verspreiden van nieuwscontent, vind je daar. Traditionele mediabedrijven zijn door dit bedrijf vervangen, zo luidt het scenario. De rol van journalisten en redacteuren is nog altijd het verzamelen van informatie, maar de verwerking ervan ligt geheel bij FutureNewsCorp, waar niet zozeer journalisten, maar vooral veel datawetenschappers en UX-designers werken.
Helberger presenteerde dit scenario als gespreksstarter op de Digital Growth Summit en liet hoofdredacteuren, CEO’s, datamanagers en strategen erop reageren. Enkele inzichten uit de sessie:
Het FutureNewsCorp-scenario voor 2034 werd breed beschouwd als ‘heel aannemelijk’.
Het idee van ‘het grote publiek’ vonden de deelnemers achterhaald in het tijdperk van AI. Volgens hen moeten nieuwsorganisaties durven afstappen van oude massacommunicatiestrategieën en meer dynamische manieren omarmen die inspelen op de wisselende behoeften van kleinere, gerichte doelgroepen.
Een duidelijke merkidentiteit wordt steeds belangrijker naarmate zorgen over nepnieuws toenemen. Deelnemers verwachten dat consumenten meer waarde zullen hechten aan de waarden achter de nieuwsbron. Een duidelijke, consistente en betrouwbare merkidentiteit zal de basis zijn voor vertrouwen als echt en AI-gegenereerd online steeds meer door elkaar gaan lopen.
Interesse om Helbergers scenario-oefening zelf te proberen? Haar slides vind je hier.
Nog eentje dan: AI in Journalism Futures
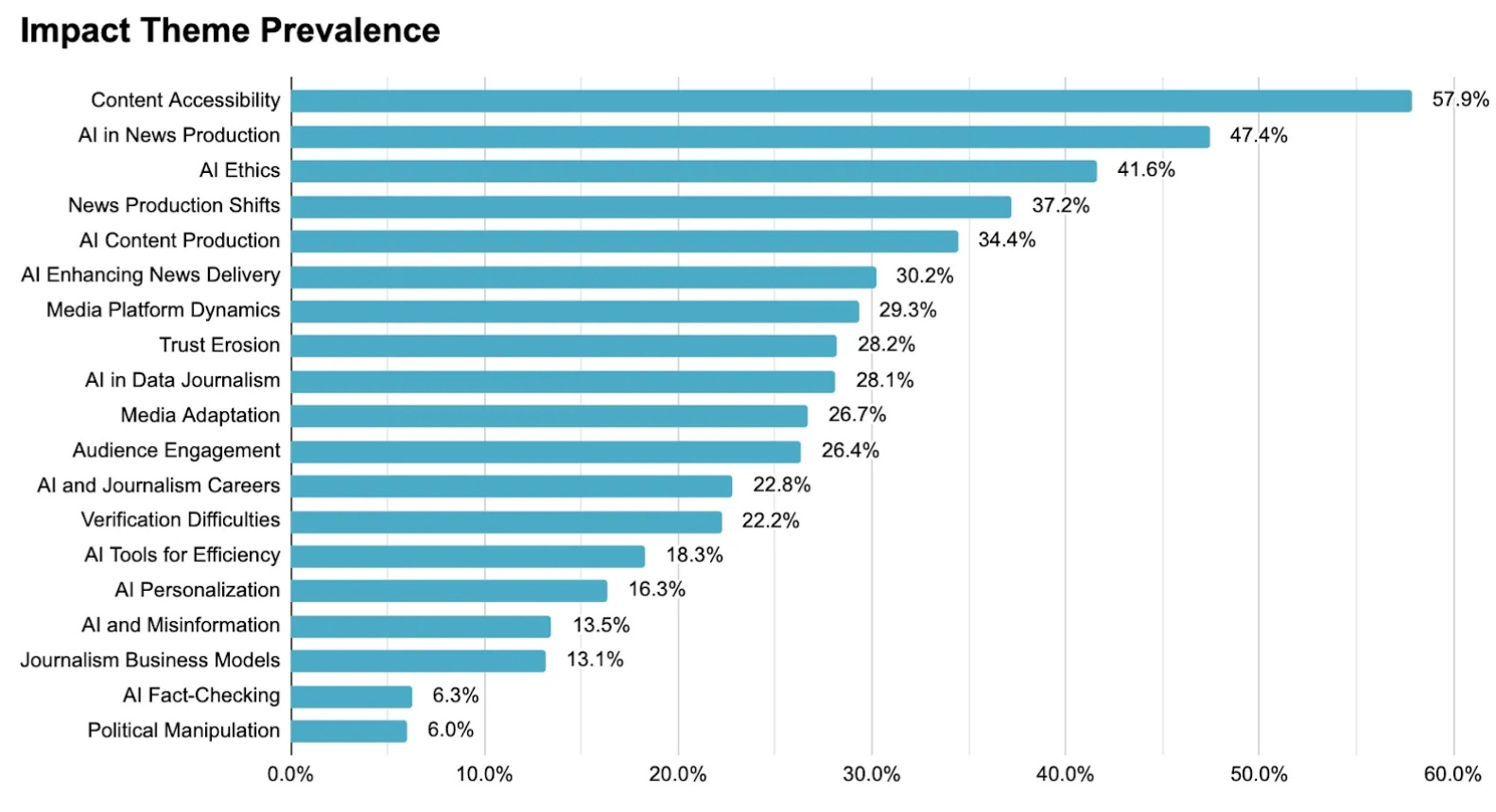
Maar liefst 852 scenario’s van deelnemers uit 70 landen verzamelde het AI in Journalism Futures project van de Open Society Foundations (OSF). Nicholas Diakopoulos (hoogleraar Computationel Journalism aan Northwestern University) analyseerde onder meer de meest voorkomende thema’s (zie afbeelding).
De scenarioschrijvers denken dat AI kan zorgen voor meer efficiëntie en dat het datajournalistiek een flinke boost zal geven, maar ze zien ook gevaren op gebied van banen en manipulatie. Tegelijkertijd worden mogelijkheden genoemd: voor verregaande personalisering met behulp van AI, voor het creëren van hyperlokale content, voor het wegnemen van taalbarrières en voor slimme factchecks.
Lezen, luisteren, kijken..

..als je vijf minuten hebt:
Op 14 oktober organiseerde ik de allereerste conferentie over AI in de journalistiek van de NVJ en Vill
amedia. Laurens Vreekamp was erbij en schreef negen hoogtepunten op.
Bellingcat brengt aan het licht dat de tool OpenDream gebruikt wordt om er kinderpornobeelden mee te genereren. De seksueel expliciete afbeeldingen én de gebruikte prompts waren maandenlang openbaar.
AI-expert Maarten Sukel trainde een model om te onderzoeken hoeveel van de dierenafbeeldingen op Google Search nog echt zijn en ontdekte dat die opvallend vaak AI-gegenereerd zijn (zie afbeelding). Waar eindigt dit en is dit het einde van zoekmachines?, vraagt Sukel zich af.

Deze man creëerde nepbands met AI en liet bots ernaar luisteren. De uitkomst: tien miljoen dollar en een arrestatie.
In NRC beschrijft Indiase technologiejournalist Nilesh Christopher de kant die AI-beïnvloeding op gaat. “‘De les die India leert is dat de vorm die we dachten dat AI-misinformatie zou aannemen, namelijk die van een realistische deepfake van een politicus, niet het primaire format is.’ Meer dan overtuigen, is het overbrengen van een gevoel of een associatie het doel, stelt Christopher. Neem Geert Wilders, die met AI zijn gedroomde Nederland tot leven wekt middels idyllische dorpsgezichten vol tulpen en blonde mensen. Dat is de metaforische kracht van AI.”
Gartners voorspellingen voor 2025 zijn uit, met aandacht voor o.a. AI-agents en broodnodige platforms die de juridische en ethische kanten van AI in de gaten houden.
Een interessante use case van de Australische omroep ABC, die test hoe Large Language Models kunnen helpen bij het genereren van titels en omschrijvingen van podcasts.

..als je iets langer hebt:
In de podcast AIToday Live is kunstenaar Julia Jansen aan het woord. In haar kunst onderzoekt zij hoe technologie, dataverzameling en AI onze samenleving beïnvloeden.
Ook in de tentoonstelling Pixel Perceptions Into The Eye Of Eye onderzoeken kunstenaars hoe AI onze beeldcultuur en beeldvorming op bewuste en onbewuste wijze beïnvloedt (Noorderlicht, Groningen, t/m 19 januari 2025).
Zin in een filmpje dit weekend? De eerste animatiefilm die een klein productieteam volledig met AI-tools maakte, is uit: Where The Robots Grow. Oordeel zelf.
Tooltips tot slot
Het Europees Parlement maakt decennia aan archieven doorzoekbaar met behulp van chatbot Archibot (gebouwd met Claude van Antropic).
Study.new genereert samenvattingen van YouTube-video’s. Even installeren en Study.new voor je YouTube-URL zetten, that’s all.
Dankjewel voor het lezen! Tips of ideeën? Mail me! (Ngoutier@villamedia.nl)
